- Basic Python fundamentals (基础的对于 Python 的了解)
- Python Environment - 可以运行 Python Notebook 的环境
Claude Model:不同模型的区别在于优化的目标不一样,对于智能和速度的平衡不一样。(intelligence & speed )
Opus : Intelligence ⬆️,适合复杂科研项目,可以持续运行数小时完成多步复杂任务 Sonnet: 智能、费用、速度的完美平衡,适合用于大多数实践场景
环境准备:Python Notebook(通常是 Jupyter Notebook)
Python Notebook(通常是 Jupyter Notebook) 是一个交互式的 Python 开发环境,常用于数据分析、机器学习、可视化和教学。你可以一边写代码一边运行,并且在同一页面展示结果(包括文字、表格、图表等)
使用 conda
conda info --envs
conda activate (envname)conda install jupyterlab
conda install notebook在目录下运行:
jupyter notebook会自动启动一个 localhost:8888 的页面。
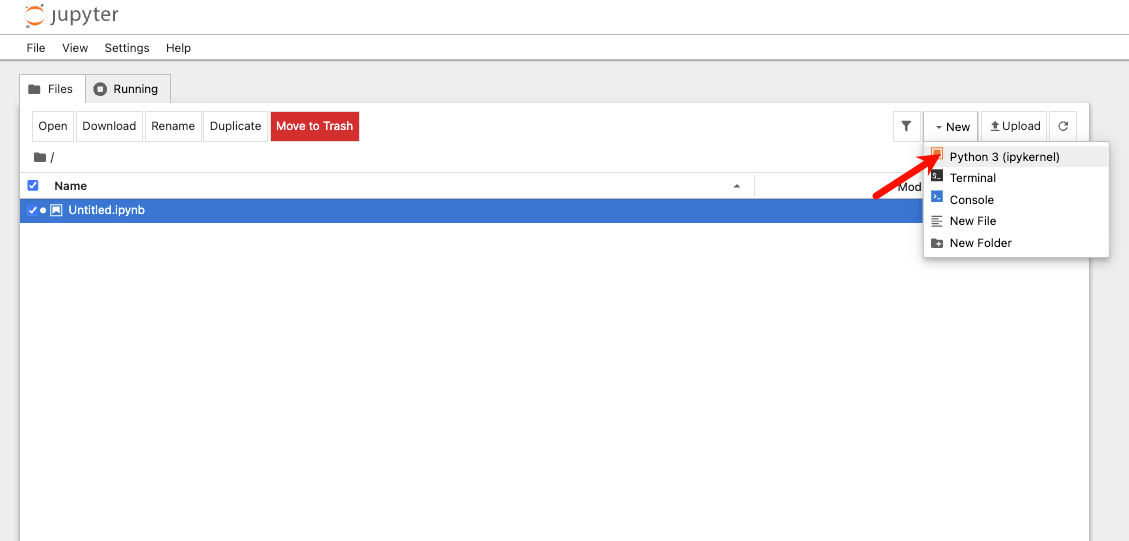
- 点击右上角 New ⇒ Python 3 (ipykernel)
在 Jupyter 网页里写代码然后 Shift + Enter 执行即可。
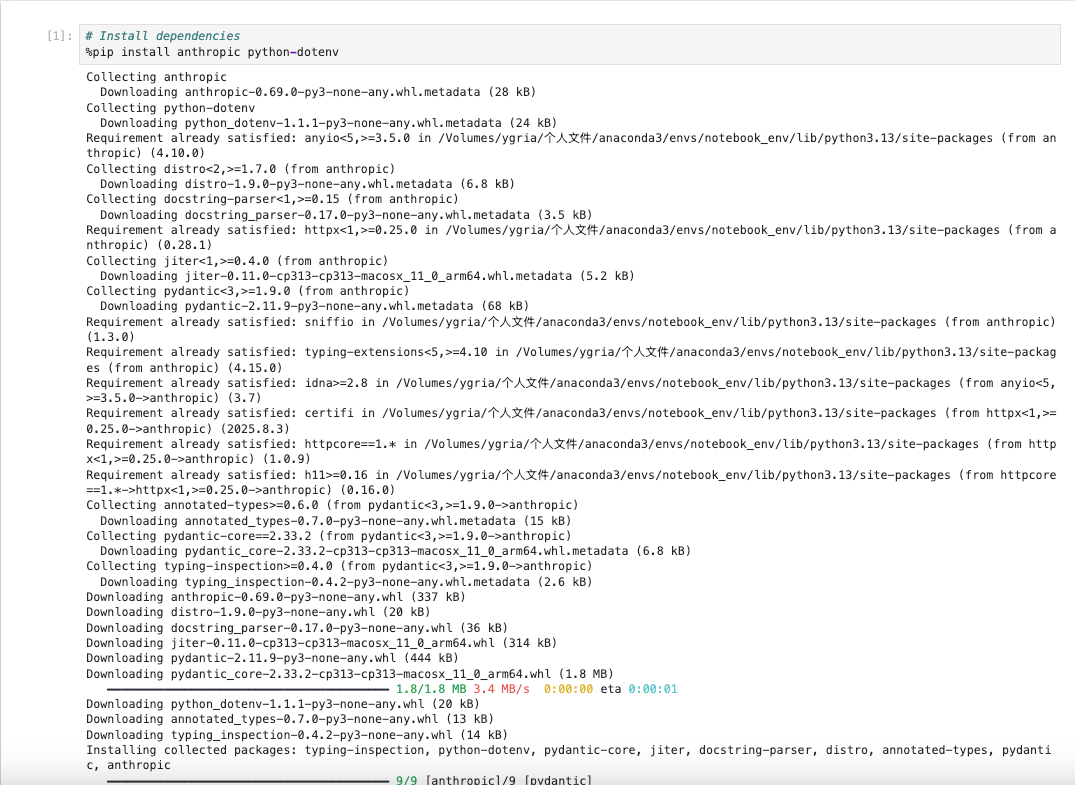
- 安装依赖 Install dependencies
Note
前面的 百分号
%是 IPython 的魔法命令(magic command),它不是普通的 Python 语法。在 Jupyter Notebook 里,如果直接写pip install,它可能会装到系统 Python,而不是当前 Notebook 内核用的 Python,导致 notebook 里还是导入不了包。所以 IPython 提供了一个 魔法命令%pip(和%conda类似),保证它会把包装到 当前内核 所用的环境。
%pip install anthropic python-dotenv
Tip
可以在 Cell 上右键 -清除 Cell Output,避免过多的日志堆积
- 将 KEY 存储在
.env文件下,这默认 Git Ignore,也就不太可能被泄漏出去。
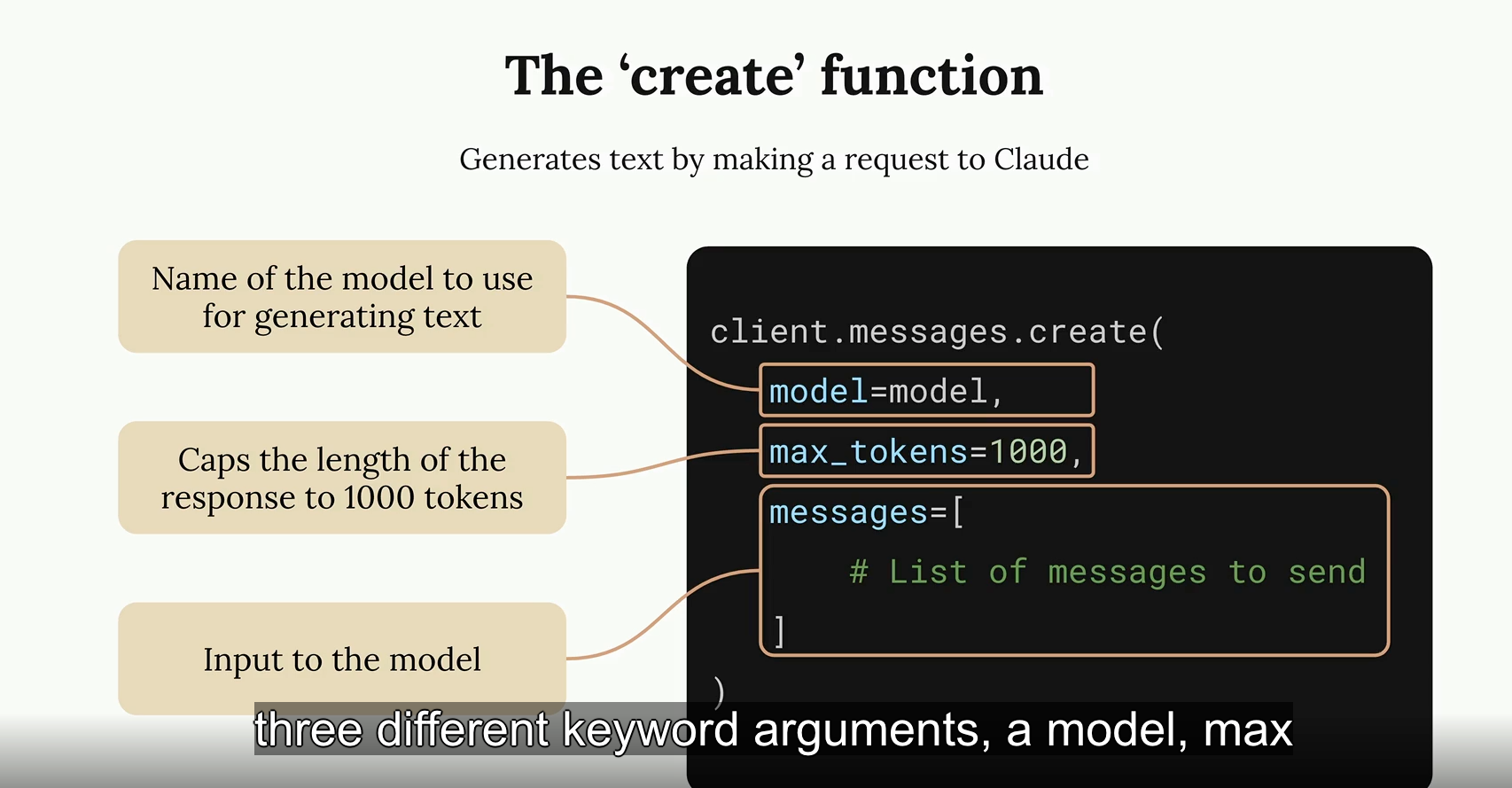
The ‘create’ function
Generate text
创建 Claude Client 的构造函数
- User Message: Content we want to feed into the model
- Assistant Message: Content the model has produced
多轮对话:模型本身不存储任何信息
为了进行多轮对话,必须将之前的模型返回的内容携带一起返回,共同构成对话的“上文”。
所以当进行对话时,必须维护一个 list 来存储与 LLM交换的所有信息,从而保留完整的上下文。
安装依赖
# Install dependencies、
%pip install anthropic python-dotenv定义环境变量
在 Notebook(.ipynb )文件平级的地方新建 .env 文件,可以自定义调用的 baseUrl 和 token
ANTHROPIC_BASE_URL="XXXXXXX"
ANTHROPIC_AUTH_TOKEN="XXXXXXX"加载环境变量
打印方法仅为了验证环境变量已经成功加载。
# Load env environment
from dotenv import load_dotenv
import os
load_dotenv()
base_url = os.getenv("ANTHROPIC_BASE_URL")
auth = os.getenv("ANTHROPIC_AUTH_TOKEN")
print("ANTHROPIC_BASE_URL=", base_url)
print("ANTHROPIC_AUTH_TOKEN =", auth)定义工具类
from anthropic import Anthropic
client = Anthropic()
def add_user_message(messages, text):
user_message = {"role": "user", "content": text}
messages.append(user_message)
def add_assistant_message(messages, text):
assistant_message = {"role": "assistant", "content": text}
messages.append(assistant_message)
def chat(messages):
# Make a request
message = client.messages.create(
model = "claude-sonnet-4-5-20250929",
max_tokens = 1000,
messages = messages
)
return message.content[0].text实际多轮对话
# Make a starting list of messages
messages = []
# Add in the initial user question of "Define quantum computing in one sententce"
add_user_message(messages, "Define quantum computing in one sententce")
# Pass the list of messages into 'chat' to get an answer
ret_message = chat(messages)
# Take the ansewer and add it as an assistant
add_assistant_message(messages, ret_message)
# add in the user's follow-up question
add_user_message(messages, "Give me another sentence")
# Call chat again with the list of messages to get a final answer
ret_message = chat(messages)Chat Bot Exercise 聊天机器人小练习
Make a chat bot using the three helper funtions we just put together.
1. Prompt the user to enter some input using the built-in "input" function
2. Add it to a list of messages
3. Call the API
4. Add generated text to the list of messages.
5. Print the generated text
6. Repeat from #1
Note
while True一直等待用户的输入- 使用
built-in的input方法,读取用户输入
简易 chatbot 代码
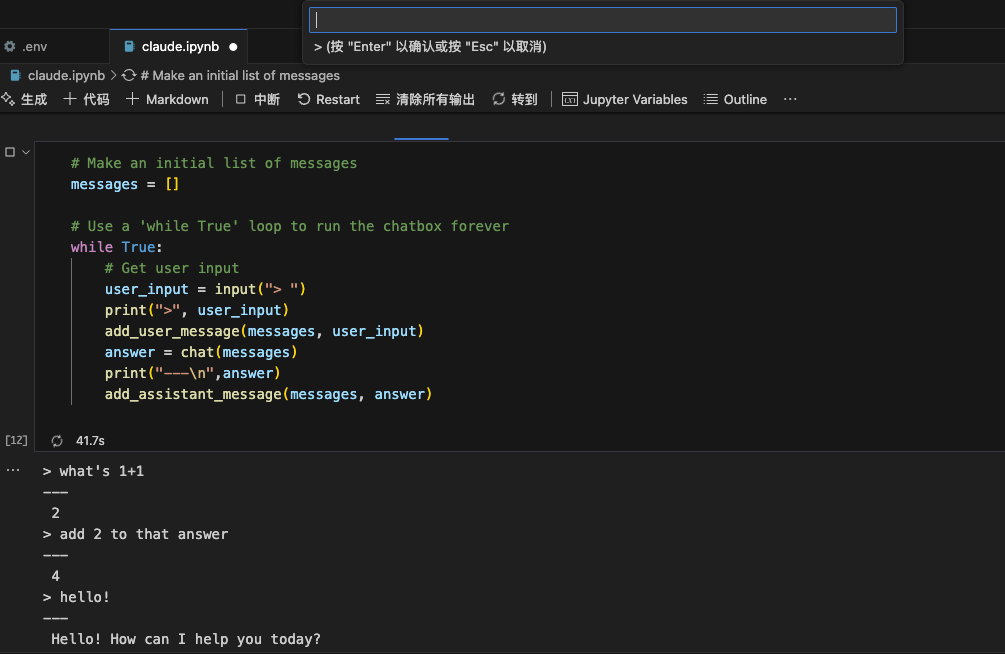
系统提示词-System Prompt-示例:Math Tutor Specialist
Note
系统级的提示词:系统级提示词是用来自定义 LLM 如何回复用户输入的。避免获得泛用回答,可以调整 LLM 的语调、风格,并能精准调试,用以实现垂直领域的用户需求。
Temperature 温度
温度时一个控制“输出随机性”的超参数,它的数值通常在 0 ~ 1 (常用范围),有时也可以>1 (极少使用)。
使用场景
根据任务不同来调整参数,越是需要严谨、不可自由发挥的场景,设置的温度应越小,越需要创意和自由发挥的场景
原理解释
在生成每个字符时都存在一定的概率:
假设让模型补全这句话:
“今天的天气真是……”
温度 0.2:
“今天的天气真是很好。”
(模型几乎总是选最高概率的词,结果非常稳定)
温度 0.8:
“今天的天气真是晴朗。”
“今天的天气真是让人心情愉快。”
(有变化,但整体合理)
温度 1.5:
“今天的天气真是一个宇宙奇观。”
“今天的天气真是蘑菇的味道。”
(可能会出现很有创意甚至奇怪的输出)
LLM 接收到数据后,会对文本内容进行分割 (break it up into small chunks), 然后猜测下一个最有可能的 token 是什么。温度就是用来“加热”或“冷却”这个概率分布的工具。

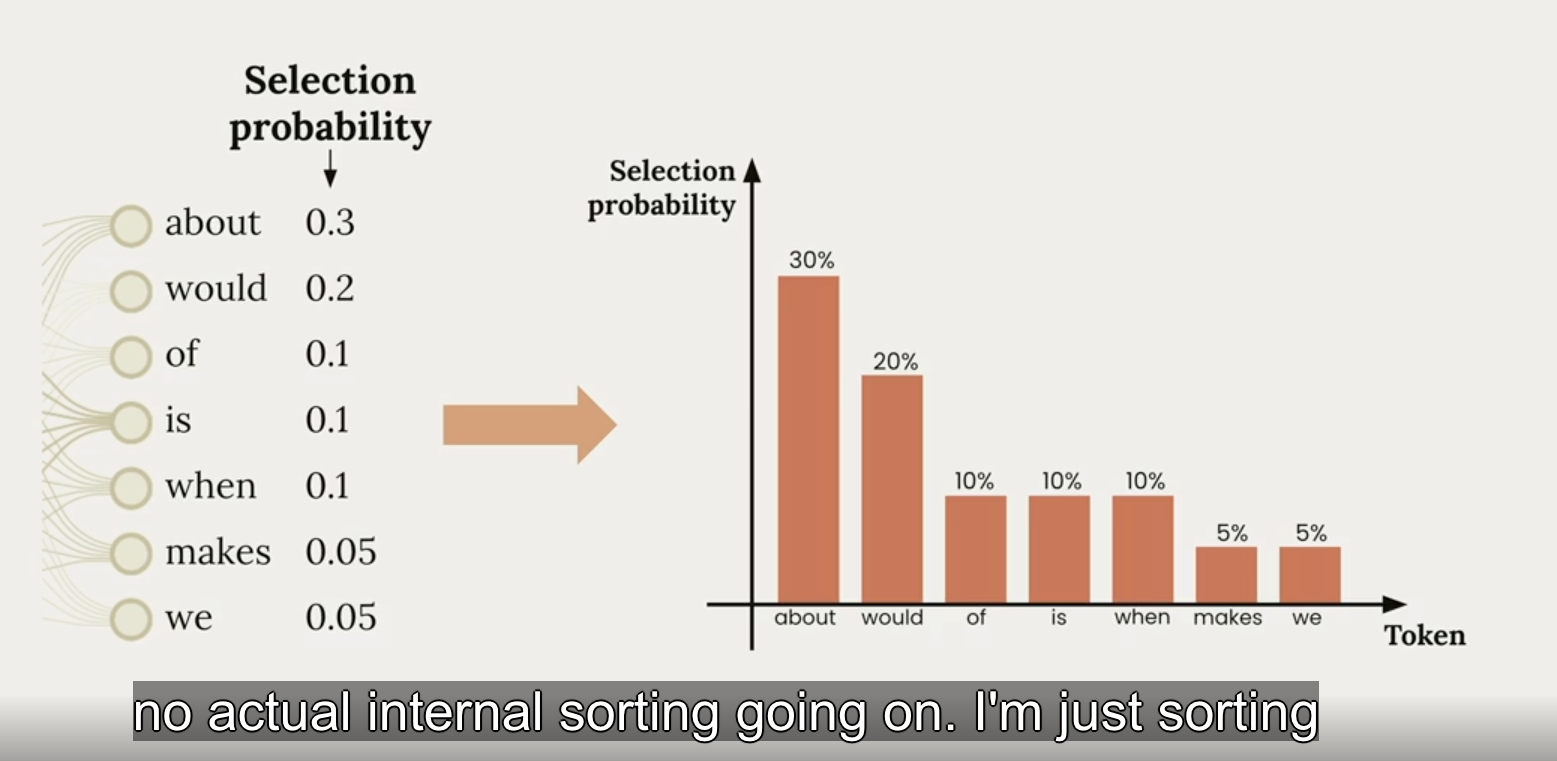
当 temperature=0 时,只会选择可能性最大的词。随着 temperature 升高,概率小的词汇的选择概率逐渐升高。下图是不同 temperature 的应用场景:

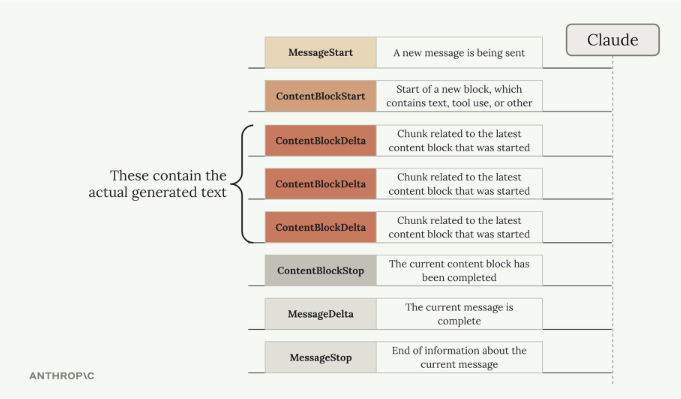
流式返回 Response Streaming
设计目的:优化用户体验。
标准返回的问题
可能需要 10-30 s(甚至更久)才能返回完整的回答内容,用户体验不佳
流式返回 Streaming
Stream Events 根据不同的方法定义,返回不同的事件类型/ 02 Stream - 流式返回